





There is a shift towards a next-generation cloud solution beyond traditional cloud services. Instead of logging into servers, serverless allows businesses to run complete functional applications through APIs. This approach empowers companies to focus on developing value-added functions and features, eliminating cost and effort barriers often associated with IT transformations.
By adopting serverless architecture, organizations can shift their IT spending from capital expenses to operating expenses throughout the entire application development process. This transition can result in a significant cost reduction of approximately 60%.
Additionally, serverless architecture offers substantial benefits for companies aiming to scale and support digital transformations, building upon the advantages of traditional cloud services while providing additional functionalities.
According to Verified market research, the Serverless Architecture Market was valued at USD 8.93 Billion in 2022 and is projected to reach USD 55.24 Billion by 2030, with a CAGR of 22.45% from 2023 to 2030. The market is experiencing significant growth due to the adoption of serverless architecture, which offers scalability, cost efficiency, and reduced operational overheads.
Despite serverless architecture being around for more than a decade, it was Amazon that revolutionized the concept with the introduction of AWS Lambda in 2014, which quickly gained widespread adoption among developers. Today, AWS Lambda remains the top choice for most developers when it comes to building serverless applications. Other leading cloud service providers, such as Google and Microsoft, also offer their own Function as a Service (FaaS) solutions, known as Google Cloud Functions (GCF) and Azure Functions respectively.
What is Serverless Computing?
Serverless computing is an evolution of cloud-computing execution models from Infrastructure-as-a-Service (IaaS) to Platform-as-a-Service (PaaS) to Function-as-a-Service (FaaS). In the realm of cloud services, there are different levels of abstraction. IaaS abstracts the underlying infrastructure to offer readily available virtual machines. PaaS takes it a step further by abstracting the operating system and middleware layer, providing an application development platform. However, FaaS goes beyond that. It abstracts the entire programming runtime, allowing developers to effortlessly deploy and execute code without the burden of deployment considerations. FaaS simplifies the process of code deployment and execution within a serverless architecture, offering a convenient and hassle-free approach.
Benefits of Serverless Computing
Serverless-based application deployment brings many benefits for DevOps engineers and organizations by fostering greater scalability, flexibility, and quicker time to release. There are several other benefits of serverless computing, such as:
- Reduced Operational Costs: Serverless architecture eliminates the need for server provisioning, maintenance, and management tasks. You only have to pay for the execution time of your functions. This means you’re not paying for idle server time, which can lead to significant cost savings.
- Scalability: Serverless applications have the ability to scale automatically. The cloud service provider runs the code in response to each individual trigger and will independently scale the application based on the number of triggers. This makes serverless ideal for applications that experience unpredictable spikes in traffic or have varying workloads.
- Developer Productivity: By abstracting away the infrastructure management complexities, the serverless architecture allows developers to focus on writing the code for individual functions, which can increase productivity. This also streamlines the development and deployment process and results in faster time to market as well.
- Automatic Backups and Security Updates: Serverless platforms include an automated backup policy and handle security and compliance updates at the infrastructure level. This reduces the burden on developers to implement and maintain backup and security systems.
- Built-in Availability and Fault Tolerance: Serverless platforms handle the underlying infrastructure and provide built-in mechanisms for fault tolerance and high availability. Functions are automatically distributed across multiple servers and regions, which ensures business resilience when an outage occurs.
The Three Key Core Technologies of Serverless Computing
Serverless computing is built around three core technologies: API Gateway, Function as a Service (FaaS), and Backend as a Service (BaaS).
- API Gateway: An API Gateway acts as a network or communication layer between the front end and the FaaS layer. Here, Rest API endpoints are mapped with the functions responsible for running business logic. In this model, there is no need to deploy and manage load balancers.
- Function as a Service (FaaS): This layer allows developers to execute the specific business logic (or code) in response to events. With FaaS, the cloud service provider automatically manages the physical hardware, VMs, OS, and web server software. It helps developers to focus solely on individual functions in application code.
- Backend as a Service (BaaS): Cloud service providers offer a range of pre-built software solutions that streamline server-based tasks, including user authentication, database management, remote updates, push notifications for mobile apps, as well as cloud storage and hosting capabilities.
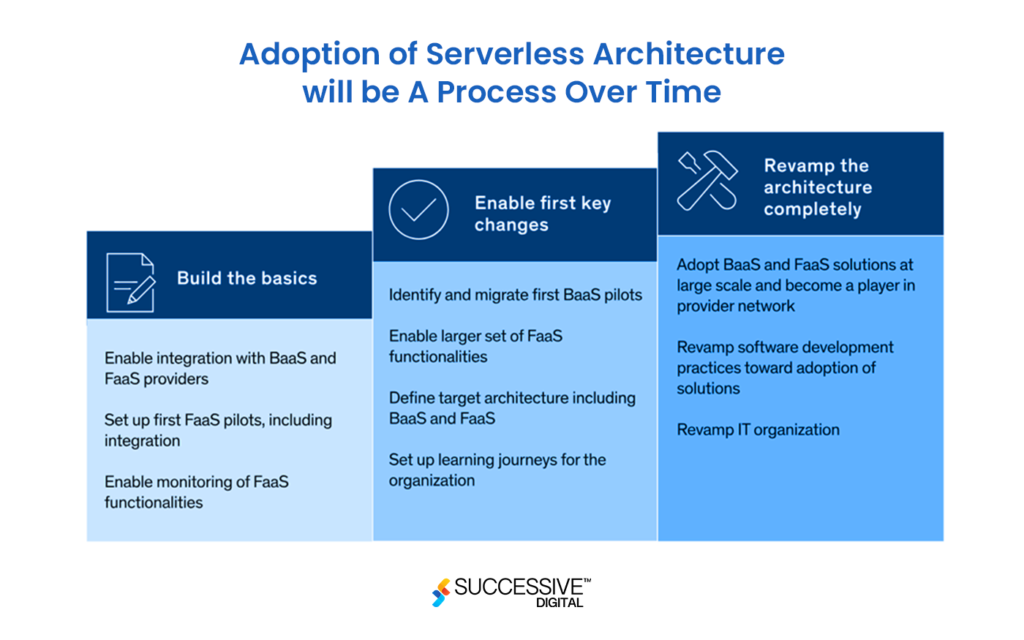
Let’s explore the steps provided by McKinsey regarding the adoption of serverless architecture:
Considering BaaS and FaaS, companies are adopting serverless architecture in three stages. First, they should lay the foundation for integrating FaaS and BaaS. Second, they should move the more significant parts of the architecture to the cloud-based FaaS and BaaS as per the targeted architecture. Last, they should adopt the new architecture with advanced technologies and functionalities.
How does Serverless Architecture Work?
Managing servers can be a time-consuming and resource-intensive task when it comes to enabling communication with applications and accessing their business logic. It involves maintaining server hardware, handling software updates and security, and implementing backups for potential failures. However, developers can shift these responsibilities to a third-party provider by adopting a serverless architecture, allowing them to concentrate on writing application code.
For instance, you can build a serverless web application along with other AWS services. As each service is fully managed, it does not require you to look after the provisoning or managing them. Just configure all the services together and upload your application code to AWS Lambda – a serverless compute service, and it will run your web application. A basic serveless application architecture often look like this with AWS services.
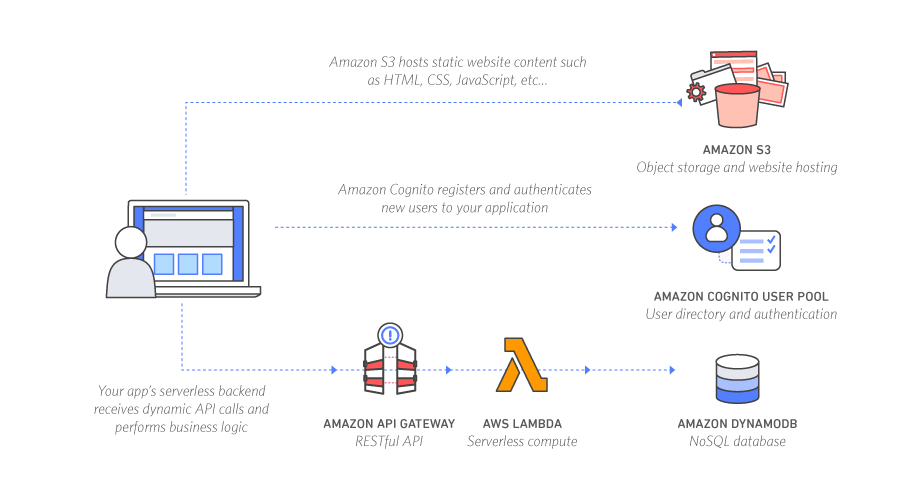
Source: AWS
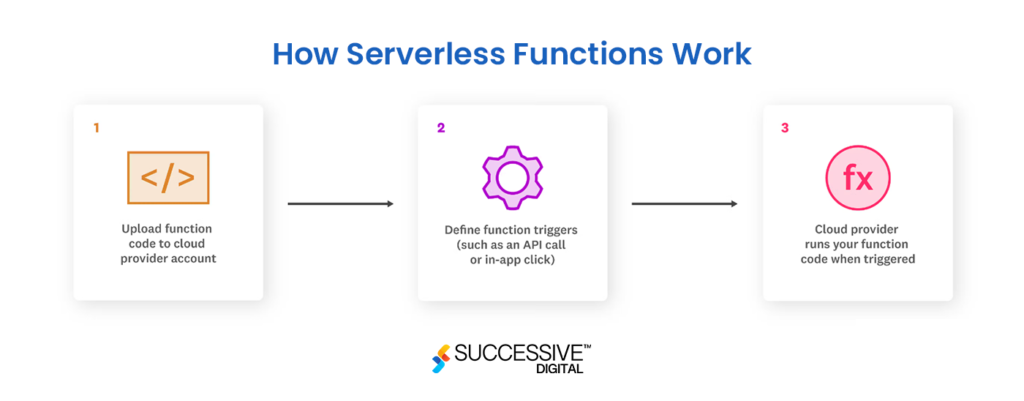
One of the most popular forms of serverless architecture is Function as a Service (FaaS). With FaaS, developers write their application code as discrete functions that perform specific tasks triggered by events like incoming emails or HTTP requests. After completing testing, developers deploy their functions and associated triggers to a cloud service provider account, and the function is invoked. Hence, the cloud service provider executes it on a running server.
If there is no active server, the provider automatically spins up a new server to handle the function. This execution process is abstracted away from developers, allowing them to focus solely on writing and deploying their application code.
Key Architectural Considerations
When designing a serverless application, there are several important considerations which needs to be put while adopting, designing, and implementing serverless computing solutions:
- Functions are Stateless: Each function is independent. The output of one function does not affect the others. This stateless nature allows for scalability and flexibility, but it also means that data persistence must be handled externally.
- Functions are Ephemeral: Functions may only last for one invocation, and developers cannot rely on the local state. This means that any long-term state must be stored in a database or other persistent storage system.
- Language Support: Different serverless providers support different languages, so you must choose a provider that supports your preferred language.
- Cold Start: The first time a function is invoked, it may take longer to start up – a phenomenon known as a “cold start”. This can impact performance, but subsequent invocations are typically faster.
- Functions Don’t Allow File Systems Level Access: Functions have certain security restrictions, including not allowing file system access. This means that any file system operations need to be handled externally.
- Functions Provide Ability to Configure Database: Functions can be set up to interact with a database, but this may require additional configuration.
- Built-in Logging & Monitoring: Serverless providers include built-in logging and monitoring, which can be used to track function performance and usage.
Conclusion
Serverless computing represents a significant shift in how we think about application development and infrastructure management. While it’s not a suitable solution to address all computing scenarios, it help companies leverage compelling benefits that make it an attractive option for many applications. As we continue to move towards a more distributed world, the importance of understanding and leveraging serverless computing will only grow.




