






All You Need to Know About GraphQL
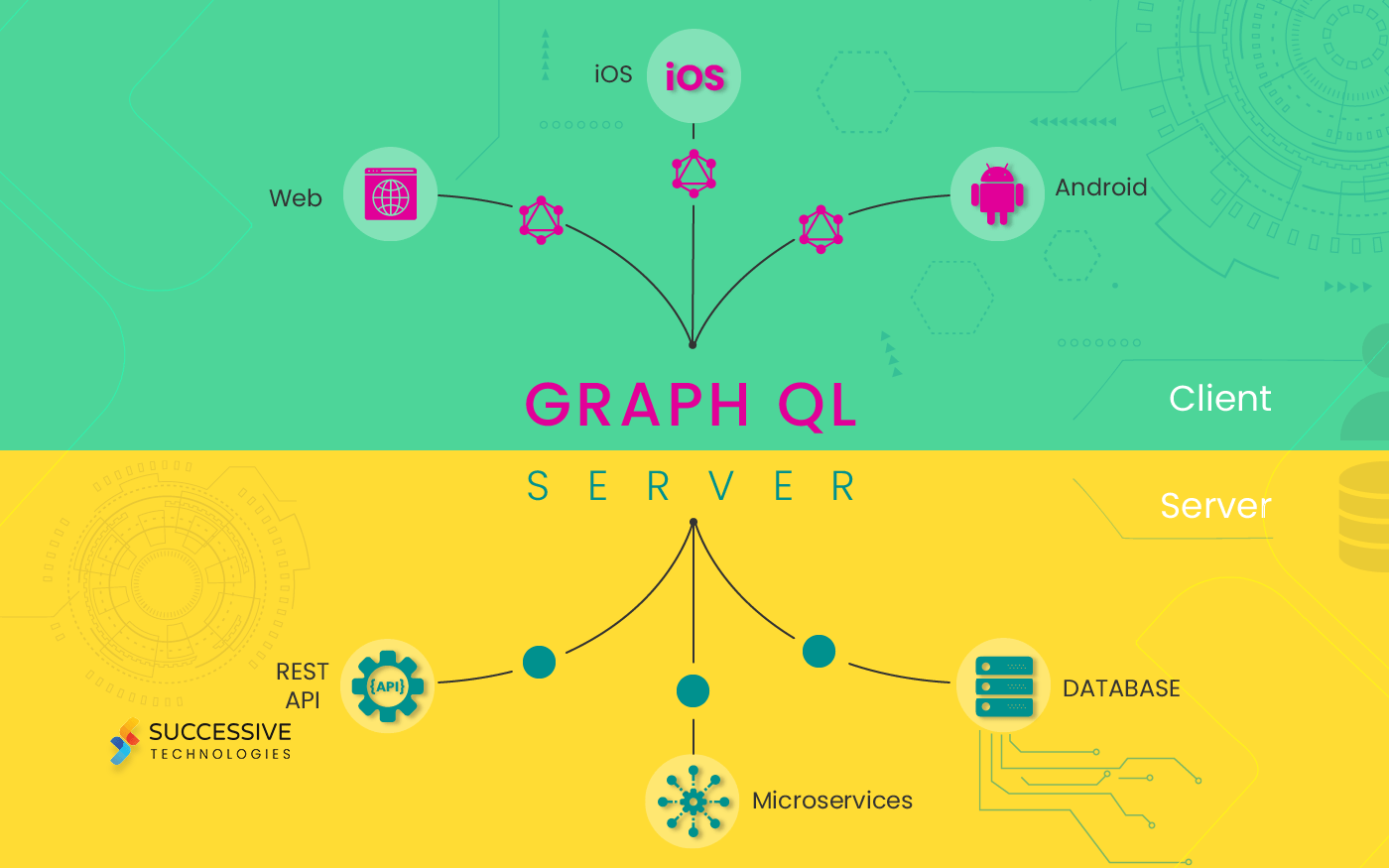
Introduction
Apollo Server is a library that helps you connect a GraphQL schema to an HTTP server in Node.js development. We will try to explain this through an example. The link used to clone this project is as follow: –
git clone https://[email protected]/prwl/apollo-tutorial.git
The best way to explain the technology and its concepts is as follows.
Challenge
Here, one of the main goals is to create a directory and install packages. It will eventually lead us to implement our first subscription in GraphQL with Apollo Server and PubSub.
Solution
For this, the first step includes building a new folder in your working directory. The current directory gets changed to that new folder, and a new folder gets created to hold your server code in and run. This will create the package.json file for us. After this, software developers install a few libraries. After installing these packages, the next step is to create an index.js file in the root of the server.
Create Directory
npm init -y
Install Packages
npm install apollo-server-express express graphql nodemon apollo-server
Connecting Apollo Server
Index.js first connects to the Apollo server. Every library will get started with the source code in the index.js file. To achieve this, web design and development companies must first import the necessary parts to start with Apollo Server in Express. Using Apollo Server’s applyMiddleware() method, you can opt-in any middleware, which is Express.
import express from ‘express’;
import { ApolloServer, gql } from ‘apollo-server-express’;
const typeDefs = gql`
type Query {
hello: String
};
const resolvers = {
Query: {
hello: () => ‘Hello World!’
}
}
`;
const server = new ApolloServer({ typeDefs, resolvers });
const app = express();
server.applyMiddleware({ app });
app.listen({ port: 4000 }, () =>
console.log(`? Server ready at http://localhost:4000${server.graphqlPath}`)
);
The GraphQL schema provided to the Apollo Server is the only available data for reading and writing data via GraphQL. It can happen from any client who consumes the GraphQL API. The schema consists of type definitions, which starts with a mandatory top-level Query type for reading data, followed by fields and nested fields. Apollo Server has various scalar types in the GraphQL specification for defining strings (String), booleans (Boolean), integers (Int), and more.
const typeDefs = gql`
type Query {
hello: Message
}Type Message {salutation: String}
`;
const resolvers = {
Query: {
hello: () => ‘Hello World!’
}
};
In the GraphQL schema for setting up an Apollo Server, resolvers can return data for fields from the schema. The data source doesn’t matter because it can be hardcoded, come from a database, or another (RESTful) API endpoint.
Mutations
So far, we have only defined queries in our GraphQL schema. Apart from the Query type, there are also Mutation and Subscription types. There, you can group all your GraphQL operations for writing data instead of reading it.
const typeDefs = gql`
type Query {
…
}type Mutation {createMessage(text: String!): String!}
`;
As visible from the above code snippet. In this case, the create message mutation accepts a non-nullable text input as an argument and returns the created message as a string.
Again, you must implement the resolver as a counterpart for the mutation. It is the same as with the previous queries, which happens in the mutation part of the resolver map:
const resolvers = {
Query: {
hello: () => ‘Hello World!’
},
Mutation: {
createMessage: (parent, args) => {
const message = args.text;
return message;
},
},
};
The mutation’s resolver has access to the text in its second argument. The parent argument doesn’t get used.
So far, the mutation creates a message string and returns it to the API. However, most mutations have side-effects because they are writing data to your data source or performing another action. Therefore, it will often be a write operation to your database for web developers, but in this case, we are just returning the text passed to us as an argument.
That’s it for the first mutation. You can try it right now in GraphQL Playground:
mutation {
createMessage (text: “Hello GraphQL!”)
}
The result for the query should look like this as per your defined sample data:
{
“data”: {
“createMessage”: “Hello GraphQL!”
}
}
Subscriptions
So far, you have used GraphQL to read and write data with queries and mutations. These are the two essential GraphQL operations to get a GraphQL server ready for CRUD operations. Next, you will learn about GraphQL Subscriptions for real-time communication between GraphQL client and server.
Apollo Server Subscription Setup
Because we are using Express as middleware, expose the subscriptions with an advanced HTTP server setup in the index.js file:
import http from ‘http’;…server.applyMiddleware({ app, path: ‘/graphql’ });const httpServer = http.createServer(app);
server.installSubscriptionHandlers(httpServer);httpServer.listen({ port: 8000 }, () => {
console.lo;
});…
To complete the subscription setup, you’ll need to use one of the available PubSub engines for publishing and subscribing to events. Apollo Server comes with its own by default.
Let’s implement the specific subscription for the message creation. It should be possible for another GraphQL client to listen to message creations.
Create a file named subscription.js in the root directory of your project and paste the following line in that file:
import { PubSub } from ‘apollo-server’;export const CREATED = ‘CREATED’;export const EVENTS = {
MESSAGE: CREATED,
};export default new PubSub();
The only piece missing is using the event and the PubSub instance in your resolver.
…import pubsub, { EVENTS } from ‘./subscription’;…const resolvers = {
Query: {
…
},
Mutation: {…
},Subscription: {messageCreated: {subscribe: () => pubsub.asyncIterator(EVENTS.MESSAGE),},},};…
Also, update your schema for the newly created subscription:
const typeDefs = gql`
type Query {
…
}
type Mutation {
…
}type Subscription {messageCreated: String!}
`;
The subscription as a resolver provides a counterpart for the subscription in the message schema. However, since it uses a publisher-subscriber mechanism (PubSub) for events, you have only implemented the subscribing, not the publishing. A GraphQL client can listen for changes, but there are no changes published yet. The best place for publishing a newly created message is in the same file as the created message:
…import pubsub, {EVENTS } from ‘./subscription’;…const resolvers = {
Query: {
…
},
Mutation: {
createMessage: (parent, args) => {
const message = args.text;pubsub.publish(EVENTS.MESSAGE, {messageCreated: message,});
return message;
},
},
Subscription: {
…
},
};…
We have implemented your first subscription in GraphQL with Apollo Server and PubSub. To test it, create a new message on a tab in the Apollo playground. On the other tab, we can listen to our subscription.
In the first tab, execute the subscription:
subscription {
messageCreated
}
In the second tab, execute the createMessage mutation:
mutation {
createMessage(text: “My name is John.”)
}
Now, check the first tab(subscription) for the response like this:
{
“data”: {
“messageCreated”: “My name is John.”
}
}
We have implemented GraphQL subscriptions.
Search
Recent Posts
-
Everything You Need to Know About Fintech Security, Risk and Compliance

-
A Pregnancy Tracking App Like Ovia: How do you Build it?
-
Scaling Ecommerce Apps: Solutions for Growing Business Demands
-
Securing Ecommerce Apps: Advanced Solutions for Data Protection
-
Utilizing Push Notifications in eommerce Apps: Strategies for Engagement and Sales


